



What is a service mesh?
A service mesh is a tool for adding security, reliability, and observability features to cloud native applications by transparently inserting this functionality at the platform layer rather than the application layer. The service mesh is rapidly becoming a standard part of the cloud native stack, especially for Kubernetes adopters.
Over the past few years, the service mesh has risen from relative obscurity to become a standard component of the cloud native stack. Linkerd (“linker-dee”), the first service mesh project, was admitted to the Cloud Native Computing Foundation in early 2017, rewritten to use Rust micro-proxies in 2018, and is now in production at organizations around the world like Microsoft, HP, and Nordstrom. In 2021 Linkerd became the only service mesh in the world to attain CNCF graduation.
But what is a service mesh, exactly? And why is it such a hot topic? In this article, I’ll define the service mesh and trace its lineage through shifts in application architecture over the past decade. We’ll take a quick look into how the service mesh works. Finally, I’ll describe where the service mesh is heading and what to expect as this concept evolves alongside cloud native adoption.
(You may also like: The Service Mesh: What Every Software Engineer Needs to Know about the World’s Most Over-Hyped Technology.)
Service mesh in a nutshell
A service mesh like Linkerd is a tool for adding observability, security, and reliability features to applications by inserting these features at the platform layer rather than the application layer.
The service mesh is typically implemented as a scalable set of network proxies deployed alongside application code (a pattern sometimes called a sidecar). These proxies handle the communication between the microservices and also act as a point at which the service mesh features can be introduced. The proxies comprise the service mesh’s data plane, and are controlled as a whole by its control plane.
The rise of the service mesh is tied to the rise of the “cloud native” application. In the cloud native world, an application might consist of hundreds of services; each service might have thousands of instances; and each of those instances might be in a constantly-changing state as they are dynamically scheduled by an orchestrator like Kubernetes. Not only is service-to-service communication in this world incredibly complex, it’s a fundamental part of the application’s runtime behavior. Managing it is vital to ensuring end-to-end performance, reliability, and security.
What does a service mesh actually do?
At its core, a service mesh adds reliability, security, and observability features to a microservice application by managing the way that communication happens between the services.
For example, Linkerd uses a wide array of powerful techniques such as mutual TLS (mTLS), latency-aware load balancing, retries, success rate instrumentation, transparent traffic shifting, and more. A single request made through Linkerd involves many steps:
- Linkerd applies dynamic routing rules to determine which destination the requester actually intended. Should the call be routed to a service on the local cluster or on remote one? To the current version or to a canary one? Each of these decision points can be configured dynamically by the operator, allowing for techniques like failover and canary deploys.
- From the set of possible endpoints to that destination (which Linkerd keeps up to date based on Kubernetes service discovery information), Linkerd chooses the instance most likely to return a fast response based on a variety of factors, including whether it’s currently serving a request as well as its recent history of latency.
- Linkerd checks to see if a usable TCP connection to that destination already exists in its connection pool. If not, Linkerd creates it, transparently using mTLS to ensure both confidentiality (encryption) and authenticity (identity validation) of both sides of the connection. Even if the communication is happening over HTTP/1.1, Linkerd may automatically establish an HTTP/2 connection to the proxy on the remote side in order to multiplex requests across a single connection.
- Linkerd attempts to send the request over the connection, recording the latency and response type of the result. If the instance is down, unresponsive, or fails to process the request, Linkerd retries the request on another instance—but only if it knows the request is idempotent and the retry budget is available. If an instance is consistently returning errors, Linkerd evicts it from the load balancing pool, to be retried later.
- Linkerd captures every aspect of the request and response in the form of metrics and distributed tracing, which are emitted and stored in a centralized metrics system and reported to the operator via Linkerd’s dashboards and CLI tools.
And that’s just the simplified version!
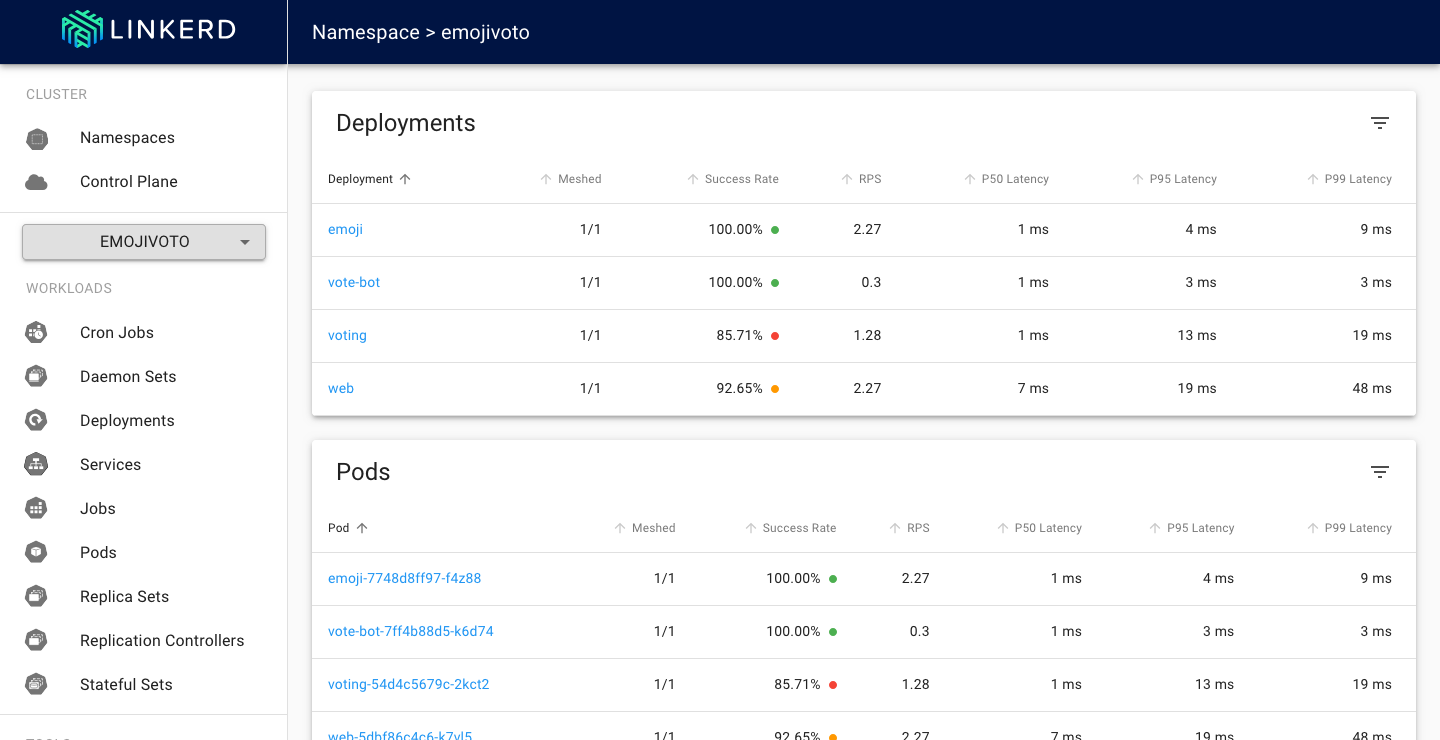
Why do I need a service mesh?
If you are building applications on Kubernetes, then a service mesh like Linkerd provides critical observability, reliability, and security features with one big advantage: the application doesn’t need to implement these features, or even to be aware that the service mesh is there!
This is great for platform teams because it aligns their responsibilities with their ownership. It’s also great for developers, as it takes features that don’t pertain to business logic off of their plates.
If you aren’t using Kubernetes, the story becomes a little muddier. Kubernetes' pod model and networking infrastructure allow service meshes to be implemented very easily with minimal operational burden. (Linkerd, for example, requires no configuration to install, even for mutual TLS!) Without these underlying features from Kubernetes, the cost of service mesh adoption starts increasing rapidly. While there are certainly “cross-platform” service meshes, the cost-benefit equation is very different, and care must be taken not to end up managing thousands of proxies by hand.
Where did the service mesh come from?
The origins of the service mesh model can be traced in the evolution of server-side applications over the past several decades.
Consider the typical “three-tiered” architecture of a medium-sized web application in the 2000’s. In this model, application logic, web serving logic, and storage logic are each a separate layer. The communication between layers, while complex, is limited in scope—there are only two hops, after all.
When this architectural approach was pushed to a very high scale, it started to break. Companies like Google, Netflix, and Twitter, faced with massive traffic requirements, implemented what was effectively a predecessor of the cloud native approach: the application layer was split into microservices, and the tiers became a topology. These systems solved this complexity by adopting a generalized communication layer , usually in the form of a library—Twitter’s Finagle, Netflix’s Hystrix, and Google’s Stubby being cases in point.
Fast forward to the modern service mesh. The service mesh combines this idea of explicitly handling service-to-service communication with two additional cloud native components. First, containers, which provide resource isolation and dependency management, and allow the service mesh logic to be implemented as a proxy, rather than as part of the application. Second, container orchestrators (e.g. Kubernetes), which provide ways of deploying thousands of proxies without a massive operational cost. These factors mean that we have a better alternative to the library approach: rather than binding service mesh functionality at compile time, we can bind it at runtime, allowing us to completely decouple these platform-level features from the application itself.
What’s the future of the service mesh?
The frantic pace of service mesh adoption is showing little sign of slowing down. As with most successful technology, the ultimate future of the service mesh is probably quite boring: to recede into the background, present but taken for granted and not actually given too much attention.
The exciting future of the service mesh, then, is not so much how the technology itself advances but rather in what it unlocks. What kinds of new things are we able to do, once a service mesh is in place? Here, the possibilities are endless!
Conclusion
The service mesh continues its meteoric rise to becoming a widely-used and critical component of the cloud native stack. From its humble beginnings as the first service mesh project in 2017, Linkerd is now in production at organizations like Microsoft, HP, and Nordstrom, and adoption shows no sign of slowing down. If you are using Kubernetes, Linkerd is fully open source and available to you today. You’re only minutes away from getting concrete, hands-on experience with the service mesh!
