

Routing
At its core, Linkerd’s main job is routing: accepting a request (HTTP, Thrift, Mux, or other protocol) and sending that request to the correct destination. This guide will explain exactly how Linkerd determines where requests should be sent. This process consists of 4 steps: identification, binding, resolution, and load balancing.
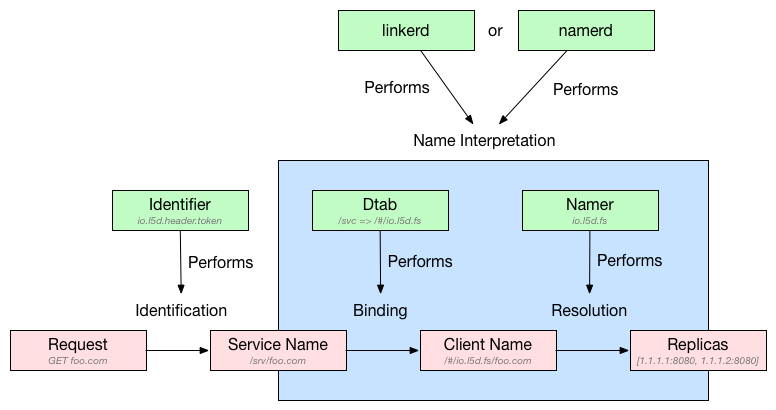
Identification
Identification is the act of assigning a name (also called a path) to the
request. A name is a slash-delimited string representing the destination of
the request. By default, Linkerd uses an identifier called
io.l5d.header.token which assigns names to requests based on the Host header
like so: /svc/<HOST>. This means that an HTTP request to
GET http://example/hello would be assigned the name /svc/example.
(Note that the path of this URL, /hello, is dropped in the name. It will still
be proxied as part of the request–the name only determines how the request is
routed, not what is sent to the destination service.)
Of course, the identifier is a pluggable module and can be replaced with a custom identifier which assigns names to requests based on any logic you desire. Learn more about Linkerd’s built in identifiers and how to configure them in the Linkerd identifier docs.
The name that the identifier assigns to the request is called the service name because it should encode the destination as specified by the application. It typically does not encode information about clusters, zones, environments, or hosts because your application shouldn’t need to worry about these concerns.
For example, if your application wants to make a request to the “users” service,
it could issue an HTTP GET request to Linkerd with “users” as the Host header.
The io.l5d.header.token identifier would assign /svc/users as
the service name of that request.
Binding
Once a service name has been assigned to a request, that name undergoes transformations by the dtab (short for delegation table). This is called binding. Detailed documentation on how dtab transformations work can be found on the Dtabs page. Dtabs encode the routing rules that describe how a service name is transformed into a client name. A client name is the name of a replica set, typically the name of a service discovery entry. Unlike service names, client names often contain details like cluster, zone, and/or environment.
client names always begin with /$ or /#. (See below for the
distinction between these two prefixes.)
Continuing the example, suppose we had the following dtab:
/env => /#/io.l5d.serversets/discovery
/svc => /env/prod
The service name /svc/users would get bound like this:
/svc/users
/env/prod/users
/#/io.l5d.serversets/discovery/prod/users
and result in /#/io.l5d.serversets/discovery/prod/users as the client
name.
Resolution
Resolution is the act of resolving a client name into a set of physical endpoints (ip address + port). Resolution is done by something called a namer which typically does a lookup into some service discovery backend. Linkerd comes with namers for most major service discovery implementations built in. Learn more about how to configure them in the Linkerd namer docs.
client names that start with /$ indicate that a namer from the
classpath should be loaded to bind that name, whereas client names that
start with /# indicate that a namer from the Linkerd config file should be
loaded to bind that name.
For example, suppose we have /#/io.l5d.serversets/discovery/prod/users as a
client name. This means that the io.l5d.serversets namer from the
Linkerd config should look up the /discovery/prod/users serverset (the result
of this lookup is a set of physical addresses).
Similarly, the client name /$/inet/users/8888 means to search the
classpath for the inet namer. This namer gets the set of addresses by
doing a DNS lookup on “users” and using port 8888.
Load balancing
Once Linkerd has a replica set, it uses a load balancing algorithm to determine where to send the request. Because Linkerd does load balancing at the request layer instead of at the connection layer, the load balancing algorithm can take advantage of request latency information to de-weight slow nodes and avoid overloading struggling hosts.