Multi-Cluster Kubernetes with Headless Services

In part two of our May Community Meeting recap blog, we’ll focus on the presentation I delivered on two Linkerd features eagerly awaited by the community: support for headless services and StatefulSets in multi-cluster environments.
I received great feedback and was asked to summarize it in this blog post. I hope you enjoy it too.
Headless services in the Kubernetes context
Before we get into the problem we are trying to solve with these new features, we need to understand headless services as a Kubernetes construct.
In Kubernetes, a normal service object represents a virtual IP address that may live in a cluster for a long time. It’s virtual because the IP address is not associated with a particular machine or endpoint. That’s because pods change so frequently in Kubernetes, that we can’t rely on IP addresses. Instead, we use services. These are virtual entry points that never change; they route requests to short-lived IPs associated with pods — an IP proxy so to speak.
A headless service is a service without an IP. But, if it has no IP, what is it used for? Well, their sole purpose is to represent a group of pods and that allows us to build network identities (and DNS entries) for this group.
Headless services and StatefulSet pods
Headless services are generally used with StatefulSet pods — a special class of pods that are long-lived and unlikely to terminate. Since a long lived pod may retain its IP address over longer periods, there is no need for a virtual IP. But there is still a need for grouping and DNS entries. And this is where headless services shine.
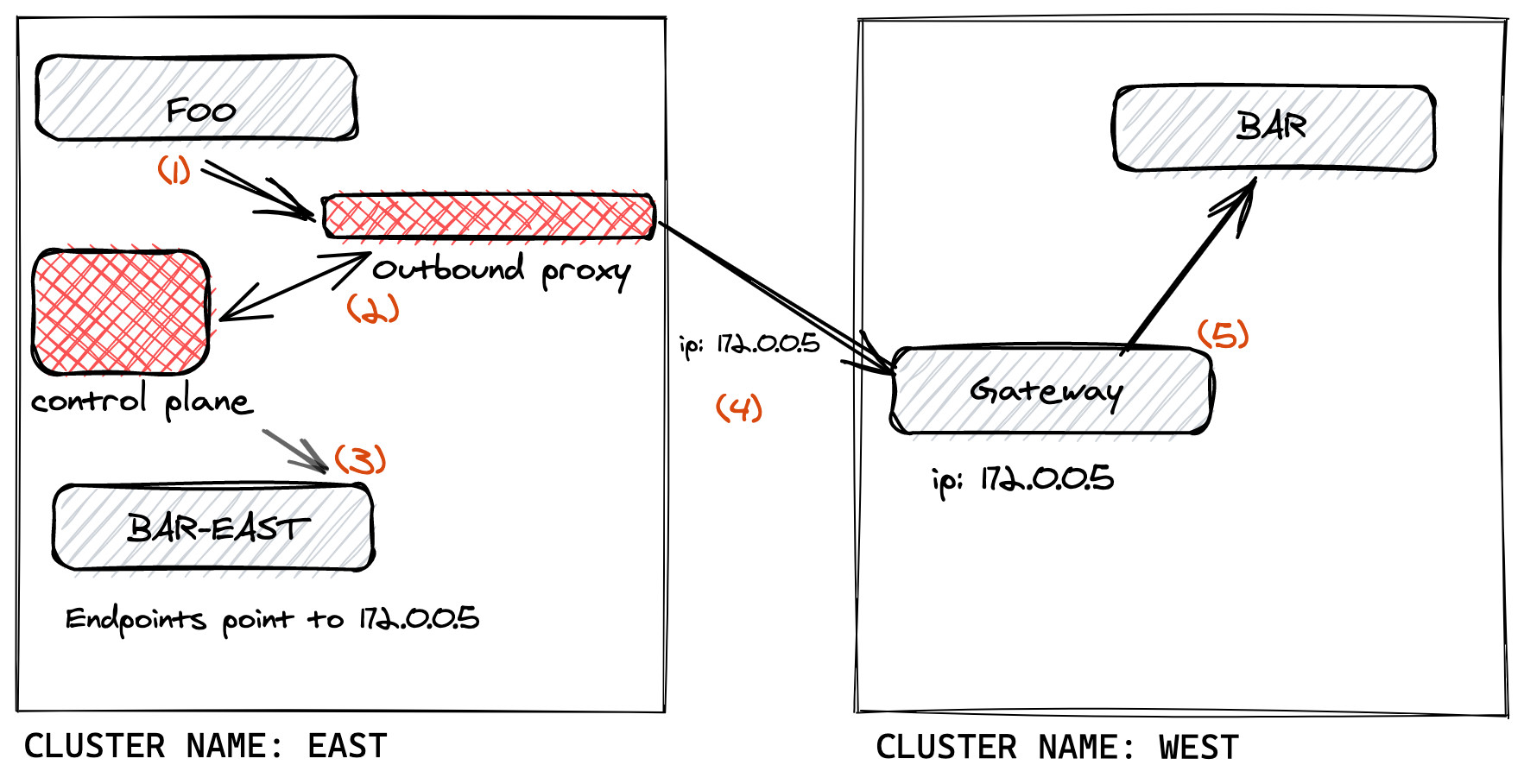
With its multi-cluster extension, Linkerd enables applications to communicate across clusters. In such an environment, there is always a source cluster from where the traffic originates and a target cluster where the traffic is going. To achieve this cross-cluster call, we replicate a target cluster service in the source cluster. Where it differs from the original service, is that this source cluster service won’t point to the server accepting the traffic, but to the target cluster gateway. When a request arrives at the gateway, Linkerd’s proxies intelligently forward the request to the server.
This is represented in Fig 1.1.: From a source cluster East, we can see the traffic originating from an application. It flows through the replicated service which points to the gateway in target cluster West. Once the traffic arrives at the gateway, it is sent to the destination.
Service replication is a big part of enabling multi-cluster communication. But how do we replicate a service without an IP address so it can point to the gateway?
Multi-cluster StatefulSet communication
Enabling a client in a source cluster to talk to a StatefulSet server in the target is easier said than done. Essentially, we want a pod to talk to another pod in a different cluster and do so efficiently and in a way that is scalable. The traditional way of replicating services no longer works. After all, we need to replicate a group that may grow or shrink at any given time.
Here’s our approach: Linkerd replicates the headless service and, for each pod in that group, also creates a new virtual entry point in the source cluster pointing to the gateway. We’ve now created a group and each member of the group can act as a synthetic pod that will lead to the gateway. Because we offload the management of replicated services to the multi-cluster component, this solution is not only scalable but also highly efficient. Traffic is handled the same way it was before but through this service indirection. Since we leverage Kubernetes primitives, we can still rely on Kubernetes to create DNS entries and assign IP addresses.
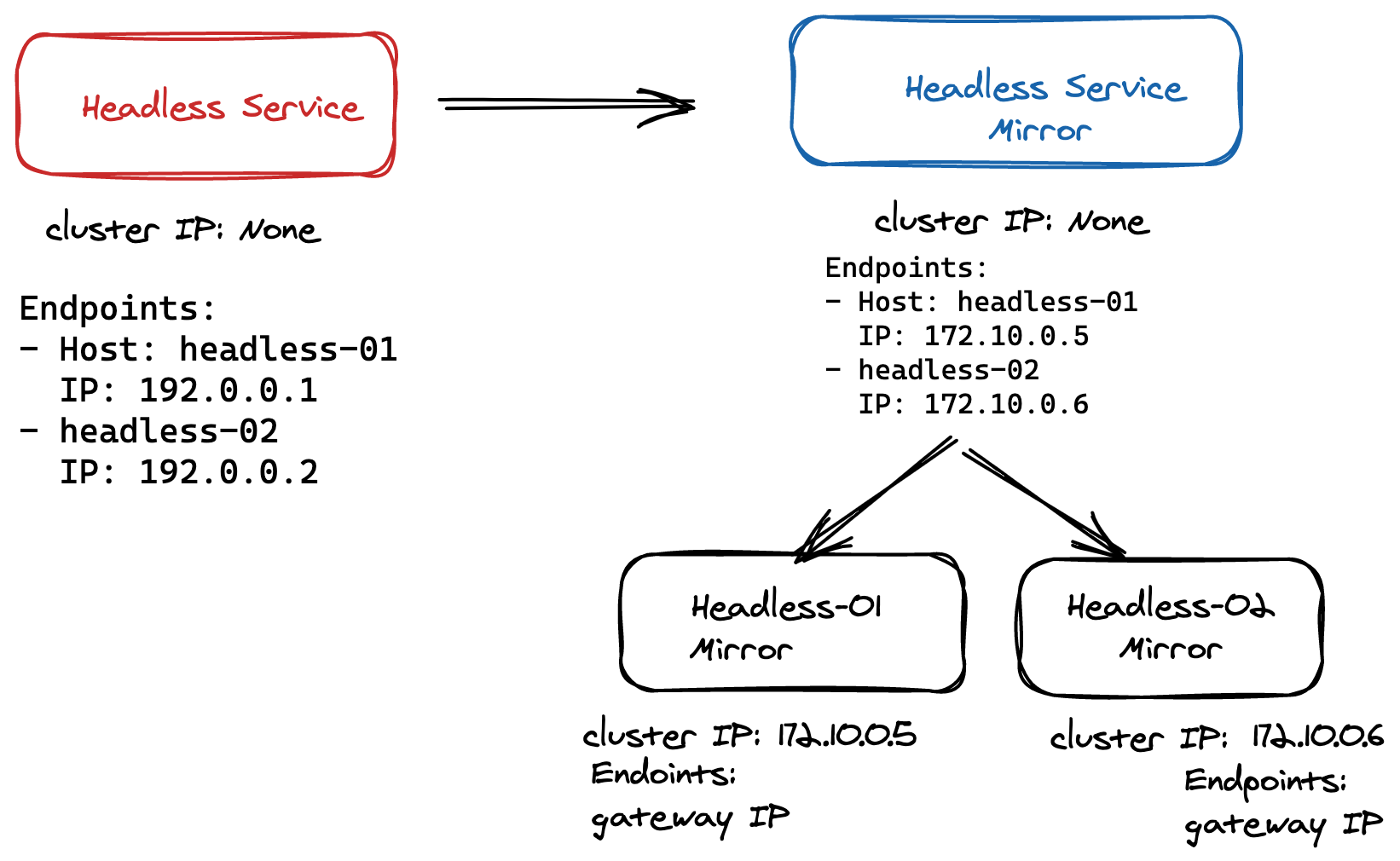
Admittedly not the simplest solution, this approach does allow us to extend Linkerd’s multi-cluster support to cover even more scenarios, especially for operators that run complex datastores and network topologies.
This concludes the May community meeting recap. Don’t wait for the next recap and join our meetup live on Thursday, July 29 at 9 AM, PT.