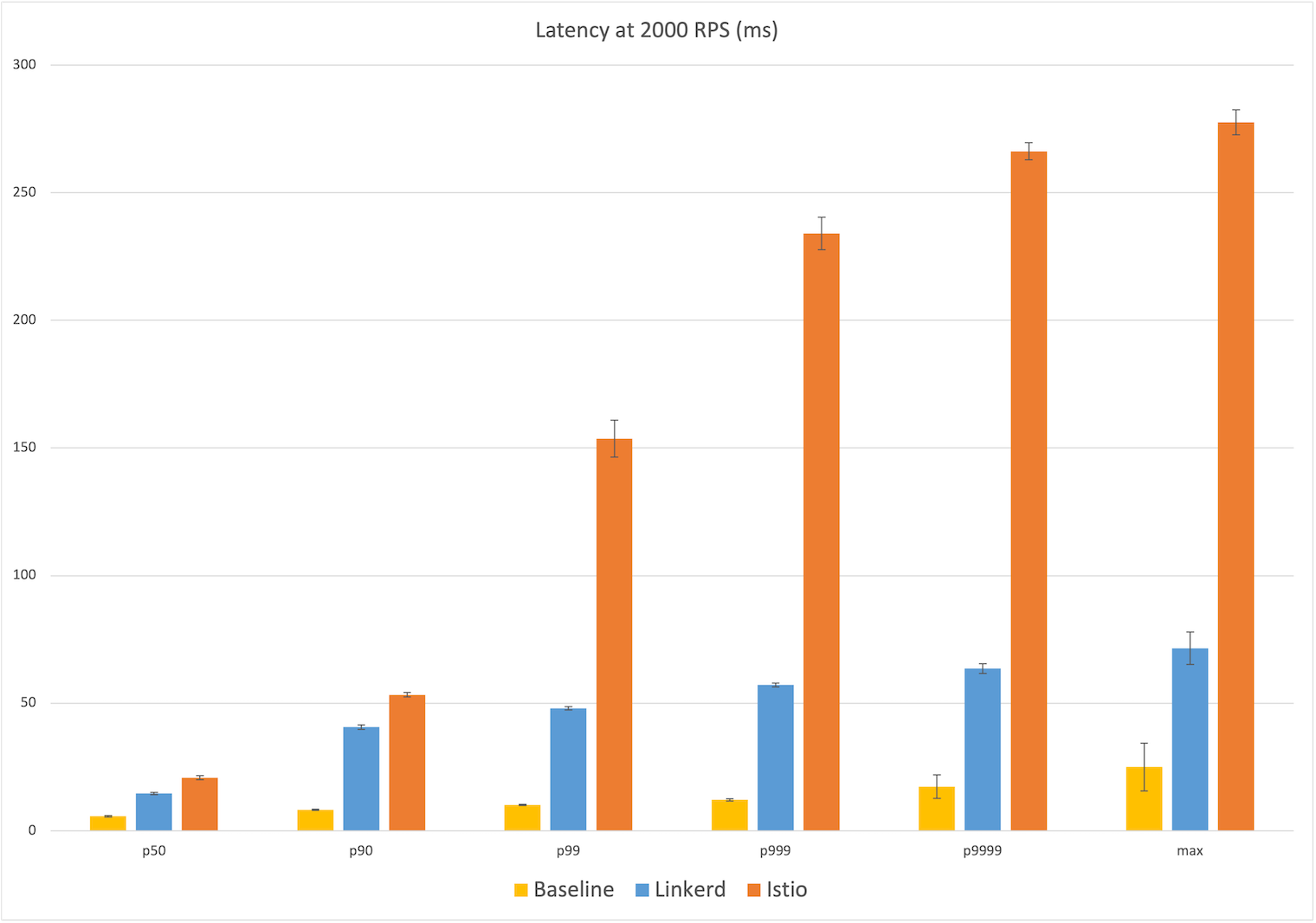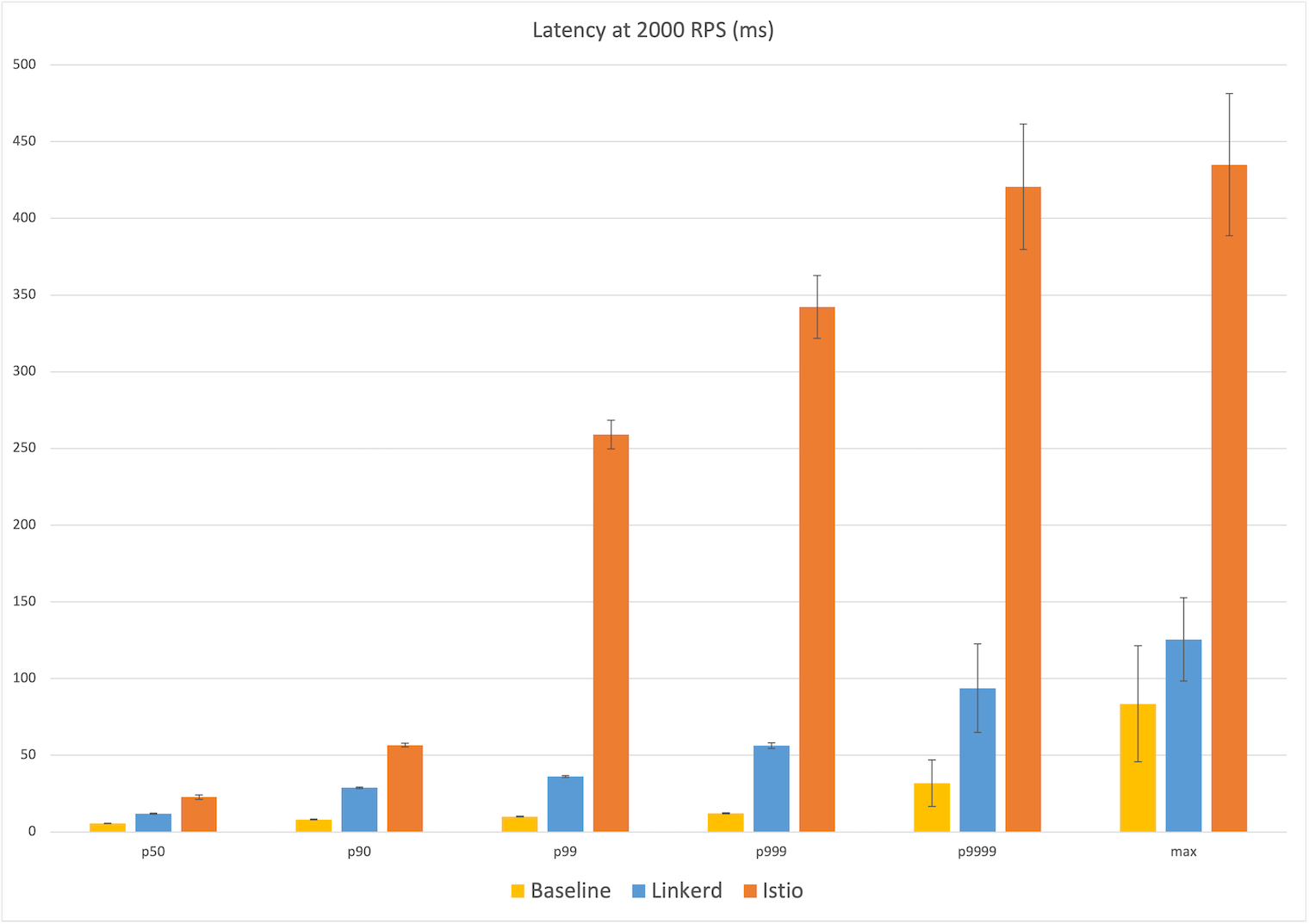

By all accounts, 2021 has been a banner year for Linkerd. The project achieved graduated status in the Cloud Native Computing Foundation, the highest possible level of project maturity. It introduced major features such as authorization policy and extensions. The Linkerd team keynoted at Kubecon EU on the many ways Linkerd is used to combat COVID-19; it published multiple benchmarks showing an order-of-magnitude performance and resource usage lead over Istio; and it continued to lead the charge on bringing Rust in the cloud native space. Linkerd’s adoption has skyrocketed this year, with organizations as wide-ranging as Microsoft, S&P Global, and Norwegian Labour and Welfare Administration, along with many others, all publicly adopting Linkerd.
Most importantly, in 2021 Linkerd helped thousands of organizations around the world adopt a modern, zero-trust approach to securing their Kubernetes clusters by providing crucial features such as zero-config mutual TLS and identity-based authorization. Not too shabby for a project that just a few years ago was still trying to explain to the world exactly what a service mesh is!
Of course, we’re not the type of project to rest on our laurels. We’ve been planning a very exciting roadmap for next year—read on for a sneak peek of what’s on the docket for Linkerd next year.
Client-side policy
In 2022 we’ll be working on adding something very important to Linkerd: client-side policy, or the ability to control traffic that’s allowed out of meshed pods. Client-side policy covers a vast set of features, including:
- Header-based routing: the ability to route traffic based on the headers of a request. This unlocks a set of advanced functionality, especially when it comes to routing within a set of services.
- Circuit breaking: the ability to automatically shut off requests to an overloaded service. While Linkerd’s sophisticated load balancing combined with plus Kubernetes’s existing health check mechanisms already provide a basic form of circuit breaking, there are some good reasons for wanting to provide more explicit configuration.
- Egress control: the ability to prevent types of traffic from exiting the cluster. While this is currently possible with things like egress gateways, this is a natural feature for client-side policy to encompass, as the data plane proxies can enforce these policies directly.
- … and lots more.
Linkerd actually already has a basic form of client-side policy in the form of ServiceProfiles, which allow you (among other things) to control the retry behavior of callers to a service. In 2.12 and beyond, we’ll be revisiting ServiceProfiles and tackling this important class of features in a more systematic way.
Multi-cluster failover
We’ve seen a clear uptick in interest from Linkerd users in the ability to automatically route traffic across clusters in the presence of a failure. For users with multiple clusters spread across regions or clouds, this ability is critical for availability goals, disaster recovery, and more.
Linkerd already provides the basic building blocks for doing this, and we’ll build mechanisms on top of these building blocks for doing automated, cross-cluster, per-service failover in a way that’s safe and sane.
Fine-grained authorization policy
In Linkerd 2.11, we introduced server-side policy, which gives you control over the traffic allowed into (as opposed to out of) meshed pods. Server-side policy added some important features to Linkerd such as authorization policy, which restricts pod-to-pod connections based on features such as workload identity.
We’ll be extending this model to cover not just workload identity but also
things like gRPC methods and HTTP verbs and routes, so that policies such as
“only allow GET requests to the /metrics endpoint over mTLS’d connections from
clients in the Foo namespace” are possible.
Mesh expansion and SPIFFE support
In 2022 we’ll be working on making Linkerd’s data plane work outside of Kubernetes. This means that Linkerd users will be able to mesh services that live outside of Kubernetes and get the same reliability, observability, and security guarantees they get for Kubernetes services today.
You can already run Linkerd’s ultralight, ultra-fast Rust proxy outside of Kubernetes today. However, in order to extend Linkerd’s operational guarantees—especially around security—to non-Kubernetes environments, we need to generalize some existing Linkerd features, notably the way it provisions workload identity. We’re looking at the SPIFFE standard as a way to do this in a non-Kubernetes-specific way.
End-of-life for Linkerd 1.x
In 2022 we will officially end-of-life Linkerd 1.x. The 1.x branch has been in maintenance mode for quite some time, and with the recent explosion of adoption for Linkerd, our efforts now need to be solely focused on Linkerd 2.x.
What about WebAssembly?
We’re keeping a close eye on WebAssembly (Wasm). As a generic mechanism for feature delivery, it doesn’t really make sense for Linkerd: Wasm imposes a significant runtime performance penalty, and for specific features it’s better to simply implement them in the proxy directly. (One of the many advantages of developing our own proxy is that we can simple do this, without fanfare and without needing to navigate competing goals between projects.) However, as a mechanism for enabling end-user plugins, Wasm may very well make sense for Linkerd, and it’s in that light that we are evaluating it.
What about eBPF?
We’re keeping a close eye on eBPF. As a technology for making network code faster, we’re all for it, and in that sense you can use Linkerd and eBPF together today. As a codename for “replacing sidecars with a per-node Envoy instance” or “replacing sidecars by putting all the logic in the kernel” we’re unconvinced. We became very familiar with the per-node model in Linkerd 1.x, and we explicitly moved away from it when designing Linkerd 2.x. The move to sidecar (per-pod) proxies in 2.x was motivated by a variety of issues we saw with Linkerd 1.x, including messy failure domains, poor separation of security concerns, and the confused deputy problem.
Of course, performance and resource consumption are critical for service meshes—we’ve regularly published competitive service mesh benchmarks and are proud of where Linkerd stands. But, to paraphrase Louis Ryan (!), eking out the last bit of performance is far less important than having good units of maintenance and isolation. We learned that lesson the hard way with Linkerd 1.x.
Whether user space or kernel space, we haven’t yet seen anything that challenges our belief that the sidecar model makes life fundamentally easier for the humans who interact with and operate the service mesh.
2022 is going to be another great year for Linkerd
Needless to say, there’s a lot more exciting and interesting work we’re planning on that didn’t make it to this list. If any of the above sounds exciting or interesting—we’d love your help. If you’ve got feature request, or think we got something totally wrong in our analysis above—let us know. And if you just want to sit back and let the features roll in, that’s fine too! After all, Linkerd is for everyone.
Linkerd is for everyone
Linkerd is a graduated project of the Cloud Native Computing Foundation. Linkerd is committed to open governance. If you have feature requests, questions, or comments, we’d love to have you join our rapidly-growing community! Linkerd is hosted on GitHub, and we have a thriving community on Slack, Twitter, and the mailing lists. Come and join the fun!
(Photo by Xan White on Unsplash.)