
Failure Injection using the Service Mesh Interface and Linkerd

Application failure injection is a form of chaos engineering where we artificially increase the error rate of certain services in a microservice application to see what impact that has on the system as a whole. Traditionally, you would need to add some kind of failure injection library into your service code in order to do application failure injection. Thankfully, the service mesh gives us a way to inject application failures without needing to modify or rebuild our services at all.
One hallmark of a well structured microservice application is that it can tolerate failures of individual services gracefully. When these failures are in the form of services crashing, Kubernetes does a fantastic job of healing these failures by creating new pods to replace the ones which have crashed. However, failures can also be more subtle, causing services to return an elevated rate of errors. These types of failures cannot be automatically healed by Kubernetes but can still cause a loss of functionality.
Using the Traffic Split SMI API to inject errors
We can easily inject application failures by using the Traffic Split API of the Service Mesh Interface. This allows us to do failure injection in a way that is implementation agnostic and works across service meshes.
We do this by first deploying a new service that returns only errors. This can be as simple as an NGINX service that is configured to return HTTP 500 responses or can be a more complex service which returns errors specifically crafted to exercise certain conditions you wish to test. We then create a Traffic Split resource which directs the service mesh to send a percentage of a target service’s traffic to the error service instead. For example, by sending 10% of a service’s traffic to the error service, we have injected an artificial 10% error rate into that service.
Let’s see an example of this in action using Linkerd as the service mesh implementation.
Example
We’ll start by installing the Linkerd CLI and deploying it on our Kubernetes cluster:
> curl --proto '=https' --tlsv1.2 -sSfL https://run.linkerd.io/install | sh
> export PATH=$PATH:$HOME/.linkerd2/bin
> linkerd install | kubectl apply -f -
> linkerd check
Now we’ll install the booksapp sample application:
> linkerd inject https://run.linkerd.io/booksapp.yml | kubectl apply -f -
One of services in this application has been configured with an error rate. The whole point of this demo is to show that we can inject errors without needing any support for this in the application, so let’s remove that configured error rate:
> kubectl edit deploy/authors
# Find and remove these lines:
# - name: FAILURE_RATE
# value: "0.5"
We should now see that the application is healthy:
> linkerd stat deploy
NAME MESHED SUCCESS RPS LATENCY_P50 LATENCY_P95 LATENCY_P99 TCP_CONN
authors 1/1 100.00% 6.6rps 3ms 58ms 92ms 6
books 1/1 100.00% 8.0rps 4ms 81ms 119ms 6
traffic 1/1 - - - - - -
webapp 3/3 100.00% 7.7rps 24ms 91ms 117ms 9
Now we can create our error service. Here I will use NGINX configured to respond
only with HTTP status code 500. Create a file called error-injector.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: error-injector
labels:
app: error-injector
spec:
selector:
matchLabels:
app: error-injector
replicas: 1
template:
metadata:
labels:
app: error-injector
spec:
containers:
- name: nginx
image: nginx:alpine
ports:
- containerPort: 80
name: nginx
protocol: TCP
volumeMounts:
- name: nginx-config
mountPath: /etc/nginx/nginx.conf
subPath: nginx.conf
volumes:
- name: nginx-config
configMap:
name: error-injector-config
---
apiVersion: v1
kind: Service
metadata:
labels:
app: error-injector
name: error-injector
spec:
clusterIP: None
ports:
- name: service
port: 7002
protocol: TCP
targetPort: nginx
selector:
app: error-injector
type: ClusterIP
---
apiVersion: v1
data:
nginx.conf: |2
events {
worker_connections 1024;
}
http {
server {
location / {
return 500;
}
}
}
kind: ConfigMap
metadata:
name: error-injector-config
And deploy it:
> kubectl apply -f error-injector.yaml
Now we can create a traffic split resource which will direct 10% of the books
service to the error service. Create a file called error-split.yaml:
apiVersion: split.smi-spec.io/v1alpha1
kind: TrafficSplit
metadata:
name: error-split
spec:
service: books
backends:
- service: books
weight: 900m
- service: error-injector
weight: 100m
And deploy it:
> kubectl apply -f error-split.yaml
We can now see a 10% error rate for calls from webapp to books:
> linkerd routes deploy/webapp --to service/books
ROUTE SERVICE SUCCESS RPS LATENCY_P50 LATENCY_P95 LATENCY_P99
[DEFAULT] books 90.66% 6.6rps 5ms 80ms 96ms
We can also see how gracefully the application handles these failures:
> kubectl port-forward deploy/webapp 7000 &
> open http://localhost:7000
Not very well, it seems! If we refresh the page a few times, we will sometimes see an internal server error page.
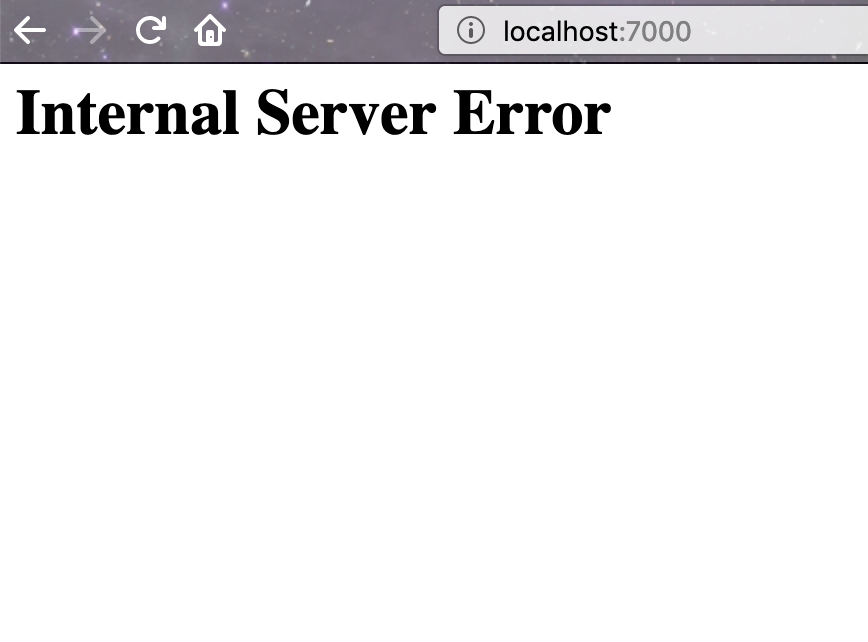
We’ve learned something valuable about how our application behaves in the face of service errors so let’s restore our application by simply deleting the traffic split resource:
> kubectl delete trafficsplit/error-split
Conclusion
In this post, we demonstrated a quick and easy way to do failure injection at the service level, by using the SMI APIs (as powered by Linkerd) to dynamically redirect a portion of traffic to service to a simple “always fail” destination. The beauty of this approach is that we are able to accomplish it purely through SMI APIs, and without changing any application code.
Of course, failure injection is a broad topic, and there are many more sophisticated approaches to injecting failure, including failing certain routes, failing only requests that match a certain conditions, or propagating a single “poison pill” request through an entire application topology. These types of failure injection will require more machinery than what is covered in this post.
Linkerd is a community project and is hosted by the Cloud Native Computing Foundation. If you have feature requests, questions, or comments, we’d love to have you join our rapidly-growing community! Linkerd is hosted on GitHub, and we have a thriving community on Slack, Twitter, and the mailing lists. Come and join the fun!




